
Request for Co-founder
This is a continuation of my RFC series, which is much in the same spirit as YC’s Request for Startups. RFC doesn’t mean “Request for Comments”—although comments are of course welcome—but rather “Request for Co-founder.” RFC posts will be deep-dives on products and problems I find interesting or that I’m particularly passionate about. Today, we’ll talk about Artificial Intelligence.
If you’re in the LA area and want to grab a coffee or a beer, don’t hesitate to reach out!
A Bloated Landscape
As I said on HN, more and more people are slowly realizing that large ML models aren’t products in themselves. At the end of the day, you need to do something like Midjourney or Copilot where there’s some semblance of value generation. Your business can’t just be “throw more GPUs at more data” because the guy down the street can do the same thing. OpenAI never had any moat, and it’s a bit telling that as early as last year, almost everyone acted as if they did. OpenAI also never really had a product.
Large machine learning models are like touch screens: technically interesting and with great upside potential. But until the iPhone, multi-touch, and the app ecosystem comes along, they’ll remain an interesting technological advancement (nothing more, nothing less).
What I’m also noticing is that very little effort (and money) is actually spent on value generation, and most is spent on pure bloat. LangChain raising $25m for what is essentially a library for string manipulation evinces a troubling trend within the AI-VC ecosystem. (N.B. I’m not solely calling out LangChain here, there are dozens of startups that have raised hundreds of millions on what is essentially AI tooling/bloat.) We need apps—real, actual, apps—that leverage these models where it matters: natural-language interaction. Not pipelines upon pipelines upon pipelines or larger and larger models that are fun to chat with but actually do basically nothing.
Generative AI \propto Value^{-1}
Even though I think that the idea that tooling doesn’t imply value is fairly noncontroversial, my first spicy take of this post is a bit stronger: the more “generative” you get with an AI product, the less value said product (excuse the pun) generates. In other words, maximizing the stochasticity of an AI solution implicitly makes the output more unpredictable, and therefore less useful. There are notable exceptions here (Midjourney being one), but even when looking at MJ, we see that the prompt-following itself must be quite reliable for the generated art to be useful.

This is why, in my view, you’ll never have AI take the jobs of creatives. AI (or at least the current SOTA transformer architecture) will likely never achieve true creativity. Using it for marketing copy or stock art generation seems fine, but it’s not really a killer product.
Similarly, Copilot, while good at boilerplate and trivial debugging, sucks at solving actual problems. And as with all projects in this vein, I fail to see the real value add. We’ve had ML-powered code generation for several years now (in fact, Copilot released publicly in late 2021), and apart from a cute novelty, there’s no real use case I’ve found. (Maybe except for generating tests, but when dealing with a novel code base, the models really can’t figure out dependency injection, mocks, weird edge cases I’d care about, etc.)
One of my favorite HN comments on this is:
If you are afraid that LLMs will replace you at your job, ask an LLM to write Rust code for reading a utf8 file character by character
—@noncoml
ChatGPT is woefully incorrect in its first attempt, and what follows is everyone trying to get the right prompt in an endless “gotcha” game of who can get the code to compile, who can better finesse the prompt, and so on. Getting LLMs to write code feels more like a game of telephone than a real useful tool.
use std::fs::File;
use std::io::{self, BufReader, Read};
fn read_file_character_by_character(path: &str) -> io::Result<()> {
// Open the file in read-only mode.
let file = File::open(path)?;
// Create a buffered reader to read the file more efficiently.
let reader = BufReader::new(file);
// chars method returns an iterator over the characters of the input.
// Note that it returns a Result<(char, usize), io::Error>, where usize is the byte length of the char.
for char_result in reader.chars() {
match char_result {
Ok(c) => print!("{}", c),
Err(e) => return Err(e),
}
}
Ok(())
}
fn main() {
let path = "path/to/your/file.txt";
if let Err(e) = read_file_character_by_character(path) {
eprintln!("Error reading file: {}", e);
}
}And, of course, browsing that thread, you have the “you need to get better at prompting” crowd and the “skill issue” crowd, and the “get better at requirements” crowd. The irony being that a verbatim solution is available on reddit and is only one Google search away.
Overall, It’s hard to see if there’s product-market fit here, at least for engineers. And if given in the hands of non-engineers, you’ll need to have an engineer at least look over the code anyway. I haven’t seen or heard of anyone that seriously uses ChatGPT to generate code and uses it in production (apart from engagement-farming “ChatGPT increased my productivity by 100x” X/Twitter posts). This AI-generated code trend reminds me of the “no-code” fad of the past 5-10 years.
In fact, even the brand new SORA seems to be suffering from the same-old generative AI pitfalls:
It has the same pitfalls as a lot of generative AI in that consistency is difficult. Control is difficult, which as creatives, I mean, you want control. That was our general feedback to the researchers: More control would be great, because we want to try to tell a story using a consistent character from shot to shot and from generation to generation. Part of that is the reason why we ended up going with the guy with the balloon for a head, because it’s a little bit easier to tell that that’s the same character from shot to shot compared to someone whose face is changing. That’s obviously an issue with it, but it’s all early days right now.
—Patrick Cederberg
What is AI Good At?
Artificial Intelligence, at least in the GPT incarnation we’re dealing with today, is, broadly speaking, pretty good at three things:
- Semantic inference (“what does this mean?”, “summarize this article”)
- Structured retrieval (“smart” needle-in-the-haystack search)
Generative (“write a story about a space-faring squirrel”)
As mentioned, I don’t think the generative aspect of AI is particularly interesting (plus, as a business opportunity, it’s also crowded), so I don’t think it’s really worth discussing. In fact, a high-schooler could probably write a more interesting story about a space-faring squirrel than GPT-4 could; and an intern can write better code than a coding model can (even if it’s just copy-pasted from Stack Overflow). So then we’re left with (1) and (2).
Once upon a time, there lived six blind men in a village. One day, the villagers told them “There is an elephant in the village today.” Since they had no idea what an elephant was, the blind men thought: “Even though we would not be able to see it, let us go and feel it anyway” and they went where the elephant was and began touching it.

—“The elephant is a pillar,” said the first man who touched its leg.
—“Oh, no! it is like a rope,” said the second man who touched the tail.
—“The elephant it is like a thick branch of a tree,” said the third man who touched the trunk of the elephant.
—“It is like a big hand fan” said the fourth man who touched the elephant’s ear.
—“No, it is like a huge wall,” said the fifth man who touched the belly.
—“It is like a solid pipe,” Said the sixth man who touched its tusk.
I bring up this age-old parable as an example of what AI models are good at: we may be blind but the model helps us see; we may be mute but the model helps us speak. In other words, large language models can fill in cognitive gaps—this often exemplifies itself as search, summarization, auto-complete, translation, and so on.
These models are fantastic at figuring out what you’re trying to do (even when you yourself aren’t exactly sure). This can be quite magical, and this is precisely the kind of product that, in my view, will be the killer app. The “elephant” in question might be 20 Slack notifications, or 15 Discord DMs, or a lengthy New York Times article, an endless list of unread emails, and so on. Every day, it seems like we’re dealing with elephants: with complex, broad, known (or unknown) corpora that we need to grok. This is (1).
Semantic Inference & Context Resolution
Apple has spearheaded some work being done in the area, and so has Google, but improving the workflows around LLM agents is, in my opinion, the first step to a killer AI app. A lot of times, the user-context-switch between OpenAI is detrimental to the user experience; the solution is purely ergonomic:

But even without the heavy lifting of screen entity encoding and/or fine-tuning a model, we have pretty stunning results. Here’s a proof of concept, a native OS widget I affectionately named Descartes:
The above is a fairly naive implementation of screen-space context resolution using screen reader APIs, but we can go even further. For example, we can augment pure textual representations with structured (or even semi-structured) data available via more traditional OS APIs. When we’re looking at a FILE_EXPLORER context (be it Finder or Windows Explorer), we populate the context with OS-provided data; in this case, file names and MIME-types. Descartes, again:
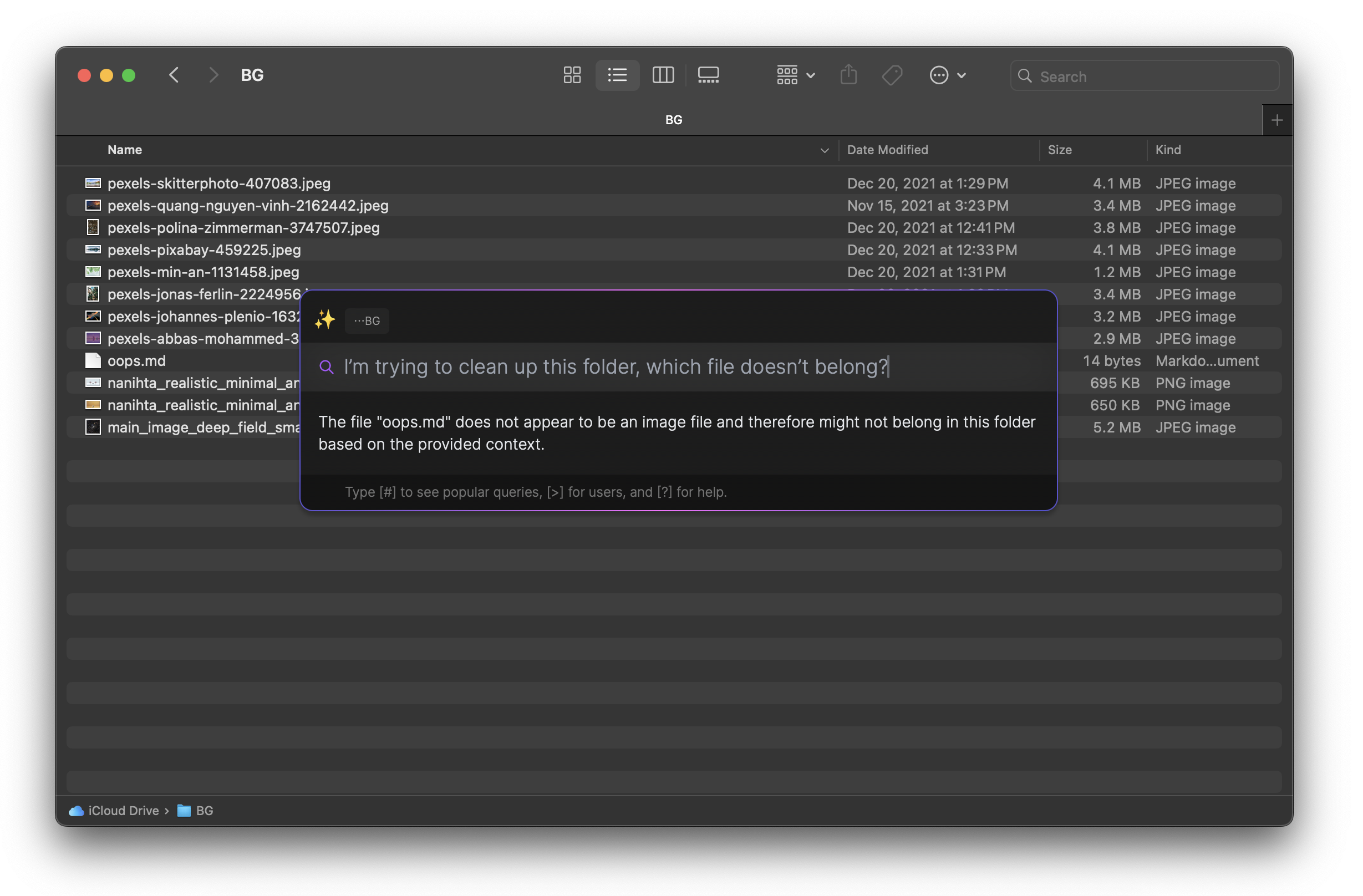
The LLM (Mistral-7B-Instruct-v0.2) successfully identifies the odd file out given the (semi-structured) generated screen-space context:
{
"app": "Finder",
"app_type": "FILE_EXPLORER",
"data": {
"path": "/Users/david/Library/Mobile Documents/com~apple~CloudDocs/BG/",
"files": "Folder path: \"/Users/david/Library/Mobile Documents/com~apple~CloudDocs/BG/\"\n\"pexels-abbas-mohammed-3680912.jpeg\", \"image/jpeg\"\n\"pexels-pixabay-459225.jpeg\", \"image/jpeg\"\n\"pexels-quang-nguyen-vinh-2162442.jpeg\", \"image/jpeg\"\n\"pexels-polina-zimmerman-3747507.jpeg\", \"image/jpeg\"\n\"main_image_deep_field_smacs0723-5mb.jpeg\", \"image/jpeg\"\n\"pexels-jonas-ferlin-2224956.jpeg\", \"image/jpeg\"\n\"pexels-johannes-plenio-1632788.jpeg\", \"image/jpeg\"\n\"oops.md\", \"text/markdown\"\n\"pexels-skitterphoto-407083.jpeg\", \"image/jpeg\"\n\"nanihta_realistic_minimal_and_conceptual_art_about_winter_91a46443-66be-4ee7-8616-e9a9048594a2.png\", \"image/png\"\n\"nanihta_realistic_minimal_and_conceptual_art_about_spring_08129fbb-d127-4953-b4a1-c32d37f20770.png\", \"image/png\"\n\"pexels-min-an-1131458.jpeg\", \"image/jpeg\"\n"
}
}Note that we aren’t even cleaning up the JSON payload much. In fact, the files field is simply a newline-delineated debug dump:
pretty_folder.push_str(&format!("{:?}, {:?}\n", file.file_name(), String::from(meta_guess)));There’s a lot of work left here: for one, context attributes should be contingent on user query. I.e.: if the user asks which the largest file is, we should be populating file sizes as well; if the user asks which file is least accessed, we should be populating access times; and so on. In an ideal world, we could populate all screen data as well as all possible metadata, but alas, LLM contexts are limited (especially when running locally), so we need to pick and choose carefully. More on this later.
But this is a glimpse into the future: the file that may not belong could be a picture of a dog in a sea of landscapes. Or a hardware invoice in a folder meant to only store software invoices. And we’re already getting into (2).
Retrieval \equiv Agentic Invocation
(2) is two-pronged: and while work is being consistently done on better data retrieval given larger and larger contexts, my argument is that data retrieval (remembering a needle) and agentic invocation (calling a function with correct arguments) are fundamentally the same thing. Both necessitate minimizing hallucination and maximizing recall correctness at arbitrary points in the token stream. Function calling is essentially curried needle-in-the-haystack search, doing exactly the same work as iterated single-data-point retrieval:
A \times B \times C \rightarrow D \equiv A \rightarrow B \rightarrow C \rightarrow D
And precisely because it’s hard (very hard, in fact), real end-user value can absolutely be created with intelligent agentic invocation. It’s when, under the hood, you get actual real results where the experience feels magical; I would argue this is why Google felt (in many ways still feels) magical: it perfected single-data-point retrieval at internet scale. Bringing this experience to consumer hardware is tantamount to building a killer AI app.
By combining the context resolution discussed in (1) with LLM tooling via common patterns like CoT or ReAcT, we can achieve relatively error-free agent invocation (using LLMs as function callers or even as tool makers). Here’s an example of Descartes combining the power of tooling with context-sensitivity:
In this demo, we have a few things going on; the details deserve their own blog post, but here’s a short rundown:
- Semantic Context Culling: trim or censor parts of the context that are not relevant to the user query; for example, non-git-URLs are not relevant to cloning a git repo
- Dynamic Tooling: only give the LLM access to tools relevant to the user query; for example, the “DATETIME” tool is not relevant to cloning a git repo
- Tool Usage Permutation: the LLM needs some examples of how to use tools; when requiring multiple tools, permute examples such that all tools are used
- Tool Invocation & Validation: tool argument validation and function calling implementation
Another example; here’s Descartes adding an event to my calendar (saves a few minutes of time, why doesn’t Google automatically do this?):
Key Takeaways
In short, my thesis is that the killer AI products will be in the same wheelhouse as apps like Dropbox or Alfred or IFTTT: productivity software that feels like an extension of the operating system.
In fact, I specifically bring up Dropbox because even though Dropbox’s original feature set (cloud file sync) has been absorbed by modern day operating systems, Dropbox has still found tremendous success.
We’ve seen some attempts of AI being coupled with operating systems (Copilot and Siri comes to mind), but large companies like Microsoft and Apple are likely too unfocused to deliver a top notch product.
And here is where a new upstart: a focused team of dedicated engineers, product visionaries, and leaders can truly make a difference: building a new way to interact with your devices.
